Google Cloud موتور ذخیرهسازی اطلاعات چند پلتفرمی جدید BigLake را راهاندازی کرد

در اجلاس Cloud Data Summit، گوگل امروز از راهاندازی پیشنمایش BigLAKE که موتور جستجوی ذخیرهسازی دادهی جدید این شرکت است خبر داد. این موتور جستجو، تجزیهوتحلیل دادهها را برای شرکتها در “دریاچهی دادههایشان” آسانتر میکند.
ایدهای که در اینجا قرار گرفته است، در هسته خود برای استفاده از تجربهی گوگل در راهاندازی و مدیریت کردن انبار داده BigQuery و گسترش دادن آن به دریاچههای داده در Google Cloud Storage است که ترکیبی از بهترین دریاچه و انبارهای داده را در سرویسی که واحد است و فضای ذخیرهسازی زیرین را انتزاعی میکند، فرمتها و سیستمهایی را ایجاد میکند.
شایان ذکر این که این دادهها میتوانند در BigQuery قرار بگیرند و یا حتی در AWS S3 و Azure Data Lake Storage Gen2 نیز مورد استفاده قرار بگیرند. از طریق موتور جستجوی دادهی BigLake، توسعهدهندگان به موتوری ذخیرهسازی و یکنواخت دسترسی پیدا خواهد کرد که به آنها این توانایی را میدهد تا از طریق سیستمی واحد، بدون نیاز به جابهجایی و یا تکثیر کردن دادهها، دادهها زیربنایی خود را جستجو کنند.
Gerrit Kazmaier، معاون و GM پایگاههای داده، بررسیها و هوش تجاری که در Google Cloud بهکار برده شده است تا در اطلاعیهای که امروز منتشر کرد، توضیح میدهد:
مدیریت دادهها در BigLake، و انبارهای متفاوت، سیلوها را ایجاد میکند که منجر به افزایش هزینه و ریسک در دادهها میشود، بهویژه در زمانیکه دادهها ملزماند تا جابهجا شوند. BigLake به شرکتها اجازه میدهد تا انبارهای داده و دریاچهها خود را برای بررسی آنها بدون اینکه نگران فرمت و یا سیستم ذخیرهسازی زیربنایی خود باشید، متحد کنند. در نهایت، اینکار نیاز به کپی کردن و یا انتقال دادهها از منبعی دیگر را از بین میبرد و هزینهی ناکارآمد آن را کاهش میدهد.
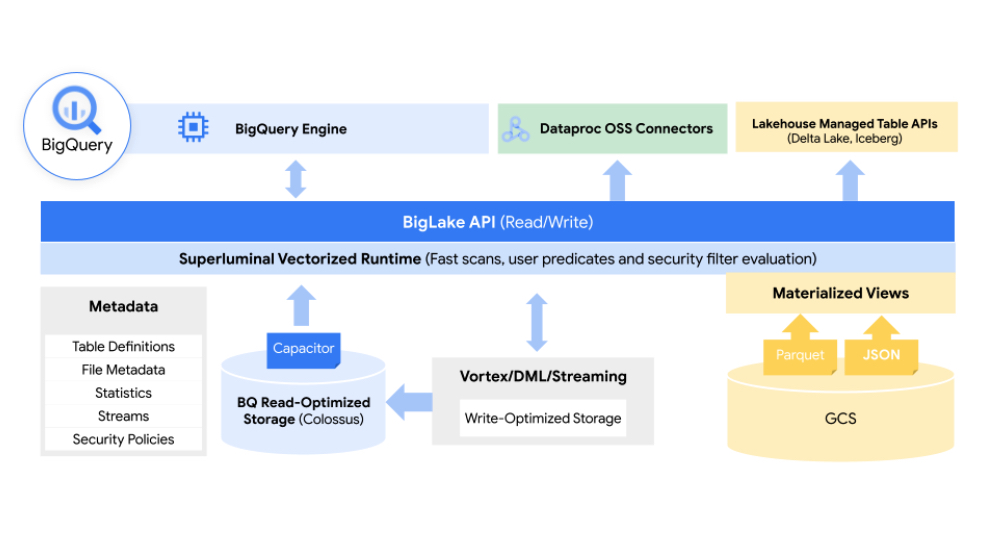
BigLke با استفاده از تگ هایی که مربوط به سیاست آن میشود، به مدیران اجازه میدهد تا سیاستهای امنیتی خود را در سطح جدول، ردیف و ستون پیکربندی کنند. این شامل دادههای ذخیرهسازیشده در Google Cloud Storage همچنین دو سیستم شخص ثالث پشتیبانیشده میشود، جای که در آن BigQuery، سرویس تجزیه و تحلیل چند ابری گوگل میتواند کنترلهای امنیتی آن را فعال کند.
سپس این کنترلهای امنیتی، تضمین میکنند که تنها دادههای مناسب را به ابزارهایی هماندد Spark، Trino، Presto و TensorFlow سرازیر میشوند. این سرویس همچنین با ابزار Dataplex Google خود با یکپارچه میکند تا قابلیتهای مدیریت دادههای اضافی را ارائه دهد.
گوگل در ادامهی بیانیهی خود اشاره کرده است که BigLake، کنترلهای دسترسی دقیقی را ارائه میکند و API آن از Google Cloud و همچنین فرمتهای فایلهای متنوع همانند Apache Parket ستونگرا و موتورهای پردازش منبعباز همانند Apache Spark استفاده میکنند.
مهندس نرم افزار Google Cloud جاستین لواندوسکی و مدیر محصول Gaurav Saxena در ادامهی اطلاعیهای که امروز منتشر شد، توضیح داد:
حجم دادههای ارزشمندی که سازمانها ملزماند تا آنها را مدیریت و تجزیه و تحلیل کنند، باسرعتی باورنکردنی درحالی افزایش پیدا کردن است. این دادهها، بهطور فزایندهای در بسیاری از مکانهایی که برخی از آنها شامل انبارهای داده، دریاچههای داده و فروشگااه NoSQL میشود، توزیع میگردد. با پیچیدهتر شدن دادهها سازمان و تکثیر پیدا کردن دادهها در محیطهای متفوات، سیلوها پدید میآیند و ریس و هزینهی بیشتری را ایجاد میکنند، بهویژه در زمانیکه آندادهها نیاز دارند تا جابهجا شوند. مشتریان ما، این روش را مشخص کردهاند؛ آنها به این کمک نیاز دارند.
علاوهبر BigLake، گوگل امروز اعلام کرد که Spanner، پایگاه دادهی SQL توزیعشده در سطح جهانی، بهزودی ویژگی جدیدی را بهنام «تغییر جریانها» در خود دریافت خواهد کرد. با استفاده از آنها، کاربران میتوانند به راحتی هرگونه تغییر را در پایگاه دادههای خود در زمانی واقعی ردیابی، بهروزرسانی و یا حذف کنند. کازمایر توضیح داد:
اینکار، به آنها تضمین میکند که همواره میتوانند به تازهترین دادههای مورد نظر خود دسترسی داشته باشند، زیرا میتوانند به راحتی تغییرات از از Spanner به BigQuery برای تجزیه و تحلیل همزمان تکرار کنند، رفتار برنامه پاییندستی را با استفاده از Pub/Sub فعال کنند و یا حتی تغییرات را در Google Cloud Storage برای انطباق آنها، ذخیره کنند.
همچنین، Google Cloud امروز Vertex Al Workbench را که ابزاری برای مدیریت همهی چرخهی حیات پروژهی داده است را خارج از نسخهی بتا، در دسترس قرار داده است و Connected Sheets را برای Looker راهاندازی کرد. همچنین، این شرکت امکان دسترسی به مدلهای دادههای Looker را در دادههای خود را در ابزار Studio Bl، راهاندازی کرد.




انتشار متن مطالب کاروتک در نشریات کاغذی یا رسانههای دیجیتال٬ بدون کسب اجازه از مدیر سایت ممنوع است.
کاری با ![]() در استودیو کارو
در استودیو کارو
