اسپاتیفای چگونه سلایق و شخصیت ما را میشناسد؟

یک مهندس نرمافزار، علم و دانش پشت توصیههای شخصیسازی شده موزیک در اسپاتیفای را توضیح و شرح میدهد. میخواهید بدانید که چگونه اسپاتیفای سلایق شما را درک میکند؟ با ما در کارو تک همراه باشید.
هر دوشنبه، درست مثل دوشنبههای دیگر ماه یا هفته، پلیلیستی تحت عنوان Discover Weekly برای صدها میلیون از کاربران اسپاتیفای نمایش داده میشود؛ یک میکس سفارشی از ۳۰ موزیک که قبلاً به آن گوش ندادهاند اما احتمالاً آنها را دوست خواهند داشت. جادویی است، مگر نه؟ پلیلیستهای Discover Weekly طرفداران زیادی در سرتاسر جهان دارد چراکه بیشتر از هر شخص دیگری (احتمالاً!) در طول زندگیتان، سلیقه موزیکتان را میشناسد و هر هفته شما را با رضایتبخشترین موزیکهای جدید، سورپرایز میکند.
اگر فکر میکنید از آن دست کاربرانی هستید که نسبت به پلیلیستهای هفتگی Discover وسواس دارید، باید بگوییم تنها نیستید: پایگاه کاربران این پلیلیست بهشکل دیوانهواری رو به افزایش است؛ موضوعی که باعث شده اسپاتیفای در تمرکز خود تجدید نظر کرده و منابع بیشتری را برای پلیلیستهای الگوریتممحور خود سرمایهگذاری کند.
Discover Weekly پلیلیستی بود که در سال ۲۰۱۵ از سوی اسپاتیفای معرفی شد و از آن زمان تا به حال، هر هفته با کاربران این پلتفرم همراه بوده است. اما سوال اصلی که از آن زمان تا به امروز ذهن بسیاری از کاربران (از جمله من) را بهخود مشغول کرده، این است که اسپاتیفای در انتخاب ۳۰ آهنگ منحصربهفرد برای کاربران مختلف در هر هفته، از چه فرآیند و دانشی استفاده می:»د؟ بیایید برای چند دقیقه به این موضوع توجه بیشتری داشته باشیم و ببینیم سرویسهای موسیقی دیگر، چگونه در توصیههای خود اشتباهاتی را پدید آوردهاند و در نهایت، اسپاتیفای چگونه توانسته این کار را بهتر انجام دهد؟
تاریخچهای بر پلیلیستهای الگوریتمی سرویسهای موزیک
در دهه ۲۰۰۰، Songza صحنه مدیریت موسیقی آنلاین را با استفاده از تنظیم دستی برای ایجاد پلیلیست از سوی کاربران متحول کرد. این بدان معنا است که تیمی از متخصصان موسیقی یا سایر متصدیان انسانی، پلیلیستهایی را که به نظر آنها خوب میآمدند را جمعآوری میکردند و سپس کاربران به آن پلیلیستها گوش میدادند. (بعدها، Beats Music نیز از همین استراتژی استفاده کرد.) مدیریت دستی یک ویژگی کاربردی بهشمار میآمد که به درستی نیز کار میکرد، اما براساس انتخابهای متصدی بود و بنابراین نمیتوانست سلیقه موسیقی فردی هر شنونده را در نظر بگیرد.

مانند Songza، سرویس Pandora نیز یکی از بازیکنان اصلی در مدیریت موسیقی دیجیتال بهشمار میآمد. این سرویس روشی پیشرفتهتر را بهکار برد و ویژگیهای آهنگها را بهصورت دستی برچسبگذاری کرد. این بدان معنی بود که گروهی از مردم به موسیقی گوش میدادند، دستهای از کلمات توصیفی را برای هر آهنگ انتخاب میکردند و براساس آن آهنگها را برچسبگذاری میکردند. سپس، کد پاندورا میتوانست بهسادگی برچسبهای خاصی را فیلتر کند تا پلیلیستهایی با موزیکهای مشابه پدید آورد.
در همان زمان، یک آژانس اطلاعاتی موسیقی از آزمایشگاه رسانه MIT به نام The Echo Nest متولد شد که رویکردی رادیکال و پیشرفته را برای موسیقیهای شخصیسازیشده پیش گرفت. Echo Nest از الگوریتمهایی برای تجزیه و تحلیل محتوای صوتی و متنی استفاده میکرد که به این سرویس امکان شناسایی موسیقی، توصیههای شخصی، ایجاد پلیلیست و تجزیهوتحلیل را میداد. در نهایت هم Last.fm را شاهد هستیم که هنوز هم وجود دارد و از فرآیندی تحت عنوان Collaborative Filtering یا لیتر مشارکتی برای شناسایی موسیقیهایی که ممکن است کاربرانش دوست داشته باشند، استفاده میکرد.
بدین ترتیب، اگر سایر سرویسهای مدیریت موسیقی به این گونه توصیهها و پلیلیستهای پیشنهادی را ایجاد میکردند، موتور جادویی اسپاتیفای به چه گونه کار میکند؟ چگونه میتوان با دقت بیشتری نسبت به سایر سرویسها سلیقه کاربران را نشان داد؟
سه نوع از مدلهای پیشنهادی اسپاتیفای
اسپاتیفای در واقع از یک مدل پیشنهادیِ انقلابی استفاده نمیکند. در عوض، آنها برخی از بهترین استراتژیهای مورد استفاده توسط سایر سرویسها را با هم ترکیب میکنند تا موتور اکتشاف منحصربهفرد خود را ایجاد کنند. برای ایجاد Discover Weekly، سه نوع مدل پیشنهادی وجود دارد که اسپاتیفای از آن استفاده میکند:
- مدلهای فیلتر مشارکتی (همان مدلهایی که Last.fm از آنها استفاده میکرد) که رفتار شما و دیگر کاربران را تحیلی میکند.
- مدلهای پردازش زبان طبیعی (Natural Language Processing یا بهاختصار NLP) که تکست و متن را تجزیهوتحلیل میکند.
- مدلهای صوتی که خود آهنگهای صوتی خام را مورد تجزیهوتحلیل قرار میدهد.
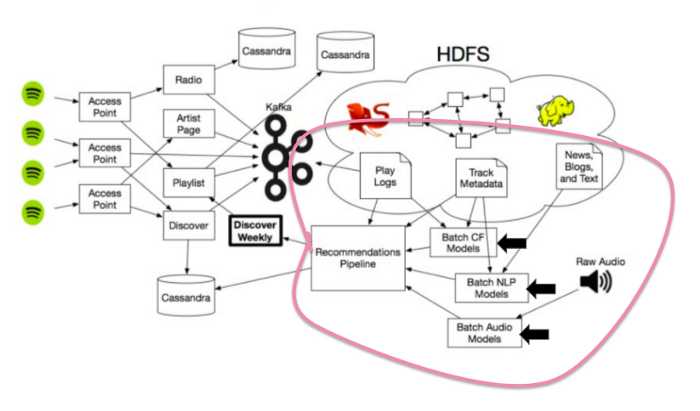
بیاییپ نحوه عملکرد هر یک از این مدلهای پیشنهادی را با یکدیگر بررسی کنیم:
مدل پیشنهادی اول: فیلتر مشارکتی یا Collaborative Filtering
ابتدا، بگذارید یک پیشینه و داستانی ارائه دهیم: وقتی مردم کلماتی همچون فیلتر مشارکتی را میشنوند، عموماً به نتفلیکس فکر میکنند چراکه نتفلیکس یکی از اولین شرکتهایی بود که از این روش برای تقویت مدل پیشنهادی استفاده کرد و از رتبهبندی فیلمهای مبتنی بر امتیازات کاربران، برای اطلاعرسانی و توصیه فیلمهای مشابه به دیگر کاربران استفاده میکرد.
پس از موفقیت نتفلیکس، استفاده از فیلتر مشارکتی بهسرعت گسترش یافت و اکنون اغلب نقطه شروع برای هر کسی است که سعی در ایجاد یک مدل پیشنهادی دارد. برخلاف نتفلیکس، اسپاتیفای سیستمی مبتنی بر ستاره ندارد که کاربران به موسیقیهای مختلف امتیاز دهند. در عوض، دادههای اسپاتیفای بازخوردمحور است؛ بهویژه، تعداد استریمهای موزیکها و دادههای اضافی استریم مثل این که آیا کاربران آهنگ را در پلیلیستهای خود ذخیره کردهاند یا خیر یا این که آیا کاربران پس از گوش دادن به آهنگ، از صفحه هنرمند آن بازدید کردهاند یا نه؟ اما واقعاً فیلتر مشارکتی چیست و چگونه کار میکند؟ در ادامه تصویری را مشاهده میکنید که در آن، افراد ترجیحات موسیقی متفاوتی دارند:

یکی در سمت چپ آهنگهای R ،Q ،P و S را میپسندد درحالی که فرد سمت راست آهنگهای S ،R ،Q و T را دوست دارد. سپس فیلتر مشارکتی با خود میگوید که: “خب، شما هر دو سه آهنگ یکسان یعنی R ،Q و S را دوست دارید، بنابراین احتمالاً کاربران مشابهی هستید. بدین ترتیب، احتمالاً از هر یک از آهنگهای دیگری که طرف مقابل گوش داده و شما هنوز نشنیدهاید، لذت خواهید برد.”
بدین ترتیب، پیشنهاد میکند که یکی در سمت راست، آهنگ P را بررسی کند؛ تنها آهنگی که ذکر نشده، اما همتای مشابه او از آن لذت میبرد و دیگری که در سمت چپ است، بههمان دلیل، آهنگ T را بررسی کند. ساده است؟ نه؟ اما اسپاتیفای واقعاً چگونه از این مفهوم در عمل برای محاسبه آهنگهای پیشنهادی میلیونها کاربر براساس ترجیحات میلیونها کاربر دیگر استفاده میکند؟ با استفاده از ماتریس ریاضیات که با کتابخانههای پایتون بهشکل عملی در میآید!
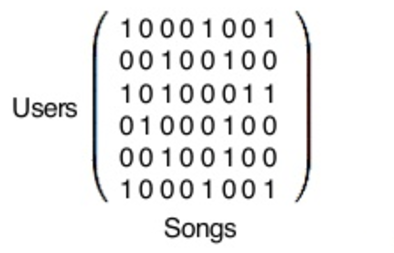
در واقع، این ماتریسی که در این جا میبینید غولپیکر است. هر ردیف یکی از ۱۴۰ میلیون کاربر اسپاتیفای را نشان میدهد (اگر از اسپاتیفای استفاده میکنید، خودتان یک ردیف در این ماتریس هستید) و هر ستون نشاندهنده یکی از ۳۰ میلیون آهنگ در پایگاه داده اسپاتیفای است. سپس، کتابخانه پایتون این فرمول فاکتورسازی طولانی و پیچیده را اجرا میکند:
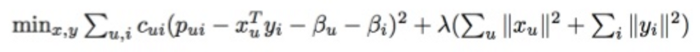
وقتی که کار تمام شد، به دو نوع بردار میرسیم که در این جا به شکل X و Y نشان داده میشوند. X بردار کاربر است که نشاندهنده سلیقه کاربران است و Y بردار آهنگ بهحساب میآید که پروفایل یک تکآهنگ را نشان میدهد. اکنون ۱۴۰ میلیون وکتور کاربر و ۳۰ میلیون وکتور آهنگ داریم. محتوای واقعی این بردارها فقط یک دسته از اعداد هستند که اساساً به خودی خود بیمعنی محسوب میشوند اما هنگام مقایسه بسیار مفید واقع میشوند.
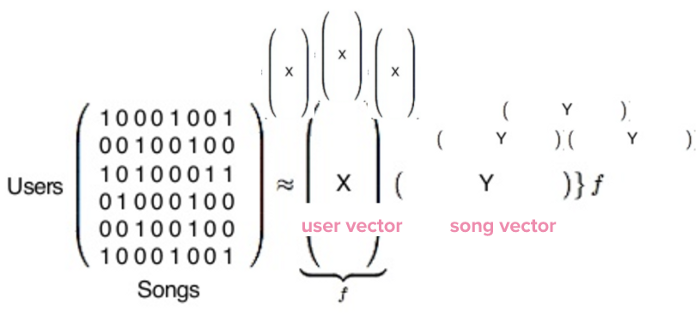
برای این که بفهمیم سلیقه موسیقایی کدام کاربران بیشتر شبیه سلیقه شما است، فیلتر مشارکتی وکتور شما را با تمام وکتورهای دیگر کاربران مقایسه میکند و در نهایت مشخص میکند که کدام کاربران نزدیکترین همخوانی را دارند. همین امر در مورد وکتور Y یعنی آهنگها نیز صدق میکند: میتوانید وکتور یک آهنگ را با تمام آهنگهای دیگر مقایسه کنید و متوجه شوید که کدام آهنگها بیشتر شبیه آهنگ مورد نظر شما هستند. فیلتر مشارکتی یک ابزار بسیار خوب است اما اسپاتیفای میدانست که میتواند با اضافه کردن یک موتور دیگر، سطح تشخیص و توصیه پلتفرم خود را بهبود ببخشد و در این برهه از زمان بود که NPL وارد ماجرا شد.
مدل پیشنهادی دوم: مدل پردازش زبان طبیعی یا Natural Language Processing
نوع دوم از مدلهای پیشنهادی که اسپاتیفای از آن استفاده میکند، مدلهای پردازش زبان طبیعی یا NPL است. دادههای منبع این مدلها همانطور که از نام آن پیدا است، کلمات قدیمی هستند: فرادادههای ردیابی، مقالات خبری، وبلاگها و سایر متنها در سرتاسر اینترنت. پردازش زبان طبیعی که توانایی یک کامپیوتر برای درک گفتار انسان شناخته میشود، یک حوزه وسیع بهشمار میآید که اغلب از طریق APIهای تحلیل احساسات و عواطف کنترل میشود.

مکانسیمهای دقیق پشت NLP خارج از محدوده این مطلب است اما آن چه در سطح بسیار ابتدایی اتفاق میافتد این است: اسپاتیفای دائماً در وب به دنبال پستهای وبلاگ و سایر متنهای نوشتهشده درباره موسیقی میگردد تا بفهمد مردم در مورد هنرمندان و آهنگهای خاص چه میگویند؛ کدام صفتها و چه زبانی بهطور مکرر در اشاره به آن هنرمند یا آهنگ استفاده میشود و کدام هنرمندان و آهنگها مورد بحث قرار میگیرند.
درحالی که نمیدانم اسپاتیفای چگونه این دادههای ناقص و خراشخورده را پردازش میکند، میتوانم اطلاعاتی را براساس نحوه کار Echo Nest بهشما ارائه دهم. آنها دادههای اسپاتیفای را به آنچه که بردارهای فرهنگی (Cultural Vectors) یا اصطلاحات برتر (Top Terms) میگویند، تبدیل میکنند. هر هنرمند و آهنگ، هزاران اصطلاحات برتر دارد که هر روز تغییر میکنند و هر اصطلاح وزن مرتبطی را بهخود اختصاص میدهد که با اهمیت نسبی آن مرتبط است؛ تقریباً احتمال این که کسی موسیقی یا هنرمند را با آن اصطلاح توصیف کند، بسیار زیاد بهشمار میآید.
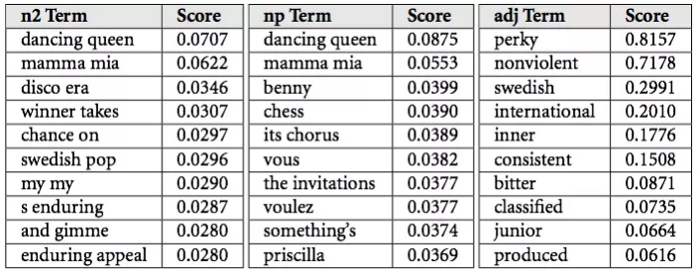
پس از آن، مانند فیلتر مشارکتی، مدل NLP از این عبارات و وزنها برای ایجاد یک نمایش برداری از آهنگ استفاده میکند که میتواند برای تعیین مشابه بودن دو قطعه موسیقی استفاده شود. زیبا است، نه؟
مدل پیشنهادی سوم: مدلهای صوتی
ممکن است به یک سؤال فکر کنید: ما در حال حاضر دادههای زیادی از دو مدل اول داریم! چرا باید خود صدا را نیز تجزیه و تحلیل کنیم؟ اول از همه، اضافه کردن مدل سوم دقت سرویس پیشنهادی موسیقی را بیشتر بهبود میبخشد. اما این مدل یک هدف ثانویه نیز دارد: برخلاف دو نوع اول، مدلهای صوتی خام آهنگهای جدید را در نظر میگیرند.
به عنوان مثال، آهنگی را که دوست خواننده و ترانهساری شما در اسپاتیفای گذاشته است در نظر بگیرید. شاید فقط ۵۰ بار گوش داده شده باشد، بنابراین تعداد کمی از شنوندگان دیگر وجود دارد که به طور مشترک آن را فیلتر کنند. همچنین هنوز در هیچ جای اینترنت از این موسیقی خبری نیست بنابراین مدلهای NLP آن را انتخاب نمیکنند. خوشبختانه، مدلهای صوتی خام بین آهنگهای جدید و آهنگهای محبوب تفاوتی قائل نمیشوند، بنابراین با کمک آنها، آهنگ دوست شما میتواند در فهرست پخش هفتگی Disvocer در کنار آهنگهای پرطرفدار قرار گیرد.
اما چگونه میتوانیم دادههای صوتی خام را که بسیار انتزاعی به نظر میرسد، تجزیه و تحلیل کنیم؟ با شبکههای عصبی کانولوشنال (Convolutional). شبکههای عصبی کانولوشنال همان فناوری مورد استفاده در نرمافزارهای تشخیص چهره هستند. در مورد اسپاتیفای، آنها برای استفاده از دادههای صوتی بهجای پیکسلها اصلاح شدهاند. در ادامه نمونهای از معماری شبکه عصبی آورده شده است:
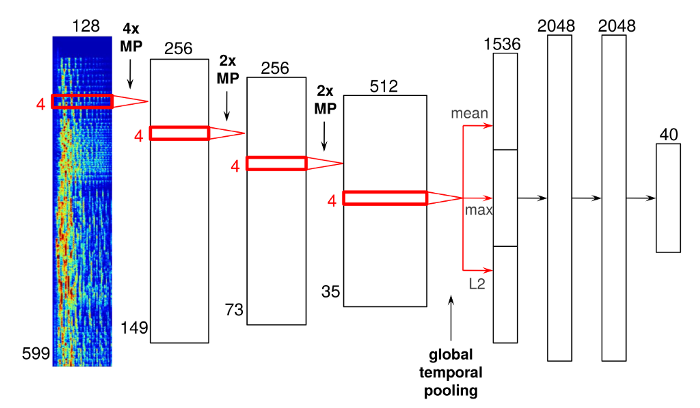
این شبکه عصبی خاص دارای چهار لایه کانولوشن است که به صورت نوارهای ضخیم در سمت چپ و سه لایه متراکم بهعنوان نوارهای باریکتر در سمت راست دیده میشوند. ورودیها، نمایش فرکانسهای زمانی فریمهای صوتی هستند که سپس به هم متصل شده تا طیفگرام را تشکیل دهند. فریمهای صوتی از این لایههای کانولوشنی عبور میکنند و پس از عبور از اخرین لایه، میتوانید یک لایه Global Temporal Pooling را ببینید که در کل محور زمانی جمع میشود و بهطور مؤثر، آمار ویژگیهای آموختهشده را در طول زمان آهنگ محاسبه میکند.
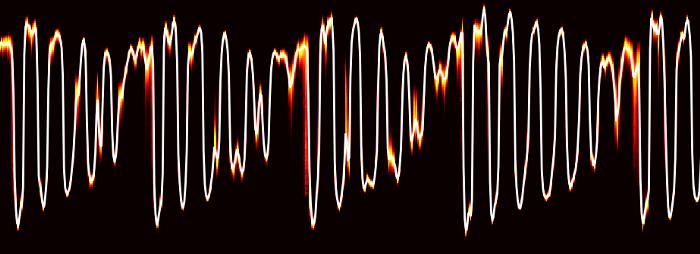
پس از پردازش، شبکه عصبی یک درک از آهنگ، از جمله ویژگیهایی مانند زمان تخمینی، کلید، حالت، سرعت و بلندی صدا را بهدست میآورد. در زیر نموداری از دادهها برای یک قطعه ۳۰ ثانیهای از موزیک Around the World که توسط دفت پانک خوانده شده، قرار گرفته است.
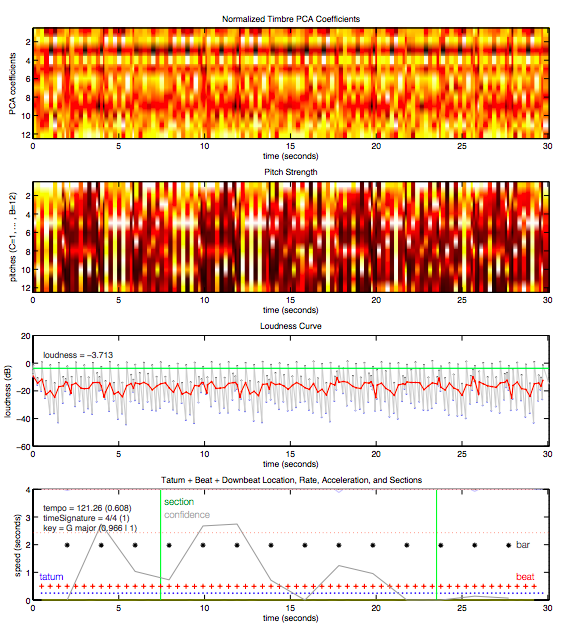
در نهایت، این خواندن از ویژگیهای کلیدی آهنگ به اسپاتیفای اجازه میدهد تا شباهتهای اساسی بین آهنگها را درک کند و بنابراین کاربران براساس سابقه شنیداری خود، از آنها لذت ببرند.
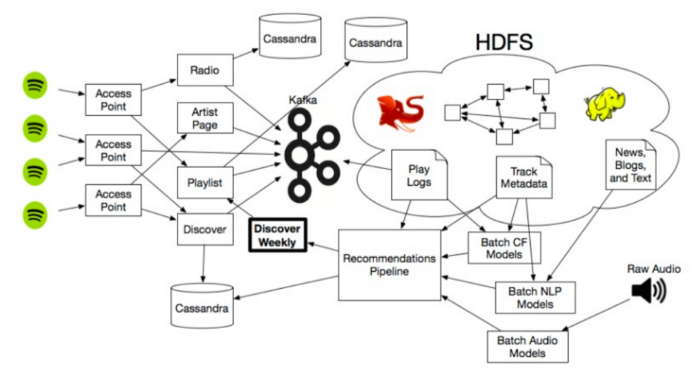
این سه نوع اصلی از مدلهای پیشنهادی را پوشش میدهد که خط لوله توصیههای اسپاتیفای را تغذیه میکند و درنهایت لیست پخش هفتگی Discover را خلق میکند. البته، این مدلهای پیشنهادی همگی به اکوسیستم بزرگتر اسپاتیفای متصل هستند که شامل مقداری عظیمی از ذخیرهسازی داده میشود و از خوشههای Hadoop زیادی برای مقیاسبندی توصیهها استفاده میکند و باعث میشود این موتورها روی ماتریسهای عظیم، مقالات موسیقی بیپایان و تعداد زیادی فایلهای صوتی کار کنند. امیدواریم این مطلب آموزنده باشد و کنجکاوی شما را نیز مانند من برانگیخته باشند.




دیدگاهتان را بنویسید
انتشار متن مطالب کاروتک در نشریات کاغذی یا رسانههای دیجیتال٬ بدون کسب اجازه از مدیر سایت ممنوع است.
کاری با ![]() در استودیو کارو
در استودیو کارو

بسیار عالی! =)))